
Python3 图片转文字服务:从原理到实践
在信息爆炸的时代,图片中的文字信息提取成为一项重要需求。无论是扫描的文档、截图中的文字,还是图片海报上的文案,将其转换为可编辑的文本都能大大提高工作效率。Python 作为一门功能强大且易于上手的编程语言,拥有丰富的库和工具,能够轻松实现图片转文字服务。本文将深入探讨如何使用 Python3 完成这一任务,涵盖实现原理、核心库介绍以及详细代码示例。
一、图片转文字的实现原理
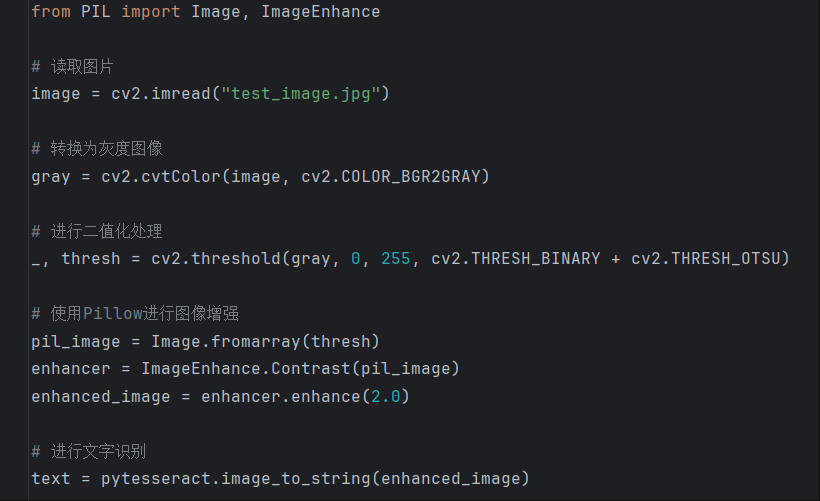
图片转文字,即光学字符识别(Optical Character Recognition,OCR),其核心原理是通过计算机视觉和机器学习算法,对图片中的文字进行检测、分割和识别。首先,图片预处理阶段会对输入图片进行灰度化、降噪、二值化等操作,以提高文字的清晰度和对比度;接着,文字检测算法会定位图片中文字的区域;然后,将文字分割成单个字符;最后,利用训练好的模型对每个字符进行识别,将识别结果组合成文本输出。
在 Python 实现过程中,主要借助第三方库来完成上述复杂的操作。通过调用这些库提供的接口,开发者无需深入了解底层算法细节,就能快速实现图片转文字功能。
二、核心库介绍
1. Pillow 库
Pillow 是 Python Imaging Library(PIL)的一个友好分支,它提供了广泛的文件格式支持、高效的内部表示以及相当强大的图像处理能力。在图片转文字任务中,Pillow 常用于图片的预处理操作,如调整图片大小、裁剪、灰度转换等。例如,使用 Pillow 打开并显示一张图片:
from PIL import Image
image = Image.open("example.jpg")
image.show()
2. Tesseract-OCR
Tesseract-OCR 是一个开源的 OCR 引擎,支持多种语言,并且可以通过训练提高识别精度。在 Python 中,可以使用 pytesseract 库来调用 Tesseract-OCR 引擎。pytesseract 库提供了简洁的接口,能够方便地将图片中的文字提取出来。在使用前,需要先安装 Tesseract-OCR 引擎(根据操作系统不同,安装方式有所差异),然后安装 pytesseract 库:
pip install pytesseract
三、结论
图片转文字服务在实际生活和工作中有广泛的应用场景,如文档数字化、发票识别、电子书文字提取等。然而,由于图片质量、字体样式、背景干扰等因素,OCR 的识别准确率可能会受到影响。为了进一步优化识别效果,可以从以下几个方面入手:
训练自定义模型:针对特定字体、语言或场景,使用 Tesseract-OCR 的训练工具,训练出更符合需求的自定义模型。
调整参数:通过调整 pytesseract 的参数,如设置语言、页面分割模式等,来提高识别准确率。
结合深度学习模型:使用基于深度学习的 OCR 模型,如百度飞桨的 PaddleOCR、Google 的 Cloud Vision API 等,这些模型在复杂场景下往往具有更好的识别效果 。
综上所述,利用 Python3 及其丰富的库,我们能够轻松实现图片转文字服务。从简单的调用库函数到结合复杂的图片预处理,再到根据实际需求进行优化,Python 为 OCR 任务提供了灵活且强大的解决方案。随着技术的不断发展,图片转文字的应用前景将更加广阔,开发者可以根据具体需求,选择合适的方法和工具,实现高效准确的文字提取功能。
上述内容展示了 Python 实现图片转文字的常见方法。若你想了解特定场景下的优化技巧,或是尝试其他库的使用,可以随时和我说。

看雪
NEVER GIVE UP.
145
文章数
99
评论量
热门文章



